科研日志
7-12
Log
- 梳理了论文 Diffusion Policy 的内容
- 在模拟环境中跑通了 ACT 训练双爪机器人递方块的流程,细节如下:
- 运行
record_sim_episodes.py生成50条脚本化数据:1
2
3
4python3 record_sim_episodes.py \
--task_name sim_transfer_cube_scripted \
--dataset_dir data/ \
--num_episodes 50 - 训练与测试:
测试结果如下:
1
2
3
4
5
6
7
8# Transfer Cube task
python3 imitate_episodes.py \
--task_name sim_transfer_cube_scripted \
--ckpt_dir data/sim_ckpt/ \
--policy_class ACT --kl_weight 10 --chunk_size 100 --hidden_dim 512 --batch_size 8 --dim_feedforward 3200 \
--num_epochs 2000 --lr 1e-5 \
--seed 0
--temporal_agg
--temporal_agg表示启用 temporal ensembling (加权平均融合),可以观察到机器人移动更平滑,卡顿明显减少,成功率比不启用时高出2个点- 测试时只需加上
--eval,测试视频存储在data/sim_ckpt/中。观察到只要夹起方块就会被脚本视为成功,即实际成功率低于测试得到的成功率 - 在生成训练数据时启用
--onscreen_render,发现夹爪行为正常,但训练出的机器人总是倾向于夹取方块底部,导致不能正对接方块的夹爪,具体原因尚不清楚
- 运行
Plan
- 到学院用4090服务器和上周采集的真实数据训练,看看效果如何
- 继续学习后面的论文
7-16
Log
- 周一到学院实验室采集了新的数据(pick_3_object)。考虑到 ACT 模型的局限性,固定了物体的摆放位置、朝向和拾取顺序,准备先试试训练效果,成功率高再尝试不同摆放位置。总共采了100条数据
- 在启智平台创建实例并保存了镜像(用于创建新实例时跳过环境搭建)并用 ACT 训练了2000个 epoch,在真实单臂机器人上测试发现夹爪会在物体正上方闭合导致抓取失败(这是常见的情况),可能是由数据采集和测试所用的摄像头不同或数据集质量不高导致的
- 对采集的数据
pick_3_objects_0714进行处理,并添加属性sim - 梳理了 ACT 的代码。其中数据填充对齐代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27# 由于采集的机器人动作序列等数据长度是随机的,在训练前需要对齐
def user_collate(datas: list, minimum_length=100):
bs = len(datas)
# 计算每个样本中非填充(有效)动作的长度(False 表示有效数据)
length_count = [(d[3] == False).sum().item() for d in datas]
# 把所有序列统一 pad 到 max_length
max_length = max(minimum_length, max(length_count))
# pad_size[i]: 第 i 个样本需要填充多少步
pad_size = [max_length - i for i in length_count]
# torch.stack()用于将多个n维张量沿着一个新的维度堆叠起来,形成一个n+1维张量
images = torch.stack([d[0] for d in datas])
qpos = torch.stack([d[1] for d in datas])
actions, is_pad = [], []
for d, l, p in zip(datas, length_count, pad_size):
curr_action = d[2][: l]
curr_pad_info = d[3][: l]
additional_pad_info = torch.ones(p, dtype=curr_pad_info.dtype, device=curr_pad_info.device) # 填充标记
pad_actions = torch.zeros((p, curr_action.shape[-1]), dtype=curr_action.dtype, device=curr_action.device) # 填充全零动作
actions.append(torch.concat([curr_action, pad_actions], dim=0))
is_pad.append(torch.concat([curr_pad_info, additional_pad_info], dim=0))
actions = torch.stack(actions)
is_pad = torch.stack(is_pad)
return images, qpos, actions, is_pad - Transformer 架构如下: 详见 d2l-transformer
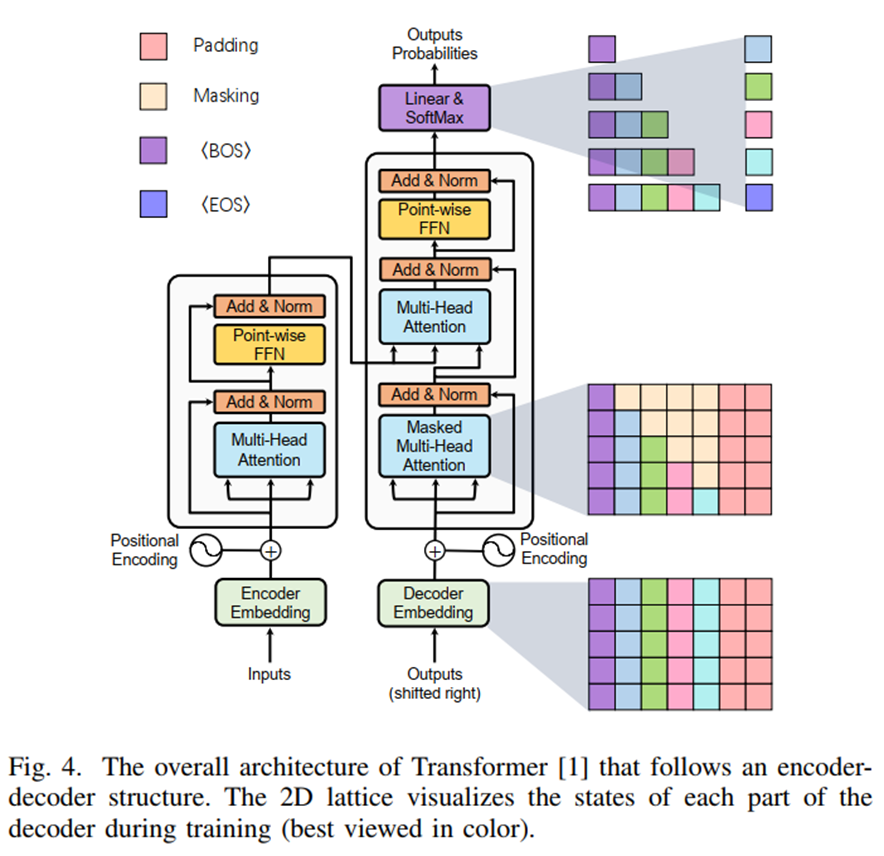 详见
详见 Plan
- 解决 aTrust vpn 的问题,在服务器上处理周一采集的数据并跑通 ACT
- 尝试用 Diffusion Policy 训练一遍,在此基础上梳理代码